
在快节奏的现代工作环境中,项目效能直接关系到团队的成败。传统效能分析依赖人工统计和经验判断,既低效又主观。Zadig 作为研发核心平台,融合丰富效能数据与大语言模型 AI,智能化分析与诊断效能数据。大语言模型可高效处理海量复杂数据,提供客观、可执行的改进建议,精准识别瓶颈,助力团队制定科学优化策略,实现效能持续提升。
本文将探讨 Zadig 如何借助大语言模型,解析用户问题关键要素,驱动智能效能分析与优化。
# 整体实现思路
核心流程分为三个步骤:首先解析用户提问的语义结构,随后从数据库检索匹配数据,最终将原始问题与关联数据整合后输入大语言模型进行智能分析。
# 1. 解析项目名称和效能评价维度
在效能诊断过程中,一般用户会输入这样的问题“分析 accout 项目近一个月的质量和效率,并给出优化建议”,系统需要将其中的项目名称(account)、时间范围(近一个月)、效能评价维度(质量和效率)解析出来。
我们利用大型语言模型(LLM)的能力,直接从用户输入中提取项目名称和效能评价维度,并将其转换为程序可处理的 JSON 格式。为了提高解析的准确性,我们还在 Prompt 中预先定义了解析规则,并提供了多个样例,利用 LLM 的小样本学习能力来提升解析的成功率。此外,我们在 Prompt 的最后明确要求 LLM 仅返回 JSON 格式的数据,以确保输出的规范性。

# 2. 处理时间范围
最初,我们尝试使用通用的 LLM 来解析时间范围,但发现结果难以使用。为此,我们引入了一个专门的 TimeNLP 服务,它能将自然语言描述的时间精确转换为程序可用的 JSON 格式。
# 3. 数据查询与预处理
在获取项目名称、效能评价维度和时间范围后,我们就可以编写相应的程序和 SQL 查询语句,从数据库中提取相关数据。为了便于后续 LLM 的理解,我们还在查询结果中添加了文字描述。文字描述确保了在后续的请求中,LLM 能够正确理解这些数据的含义。
# 4. 处理大 Token 数据
在实际操作中,我们发现输入数据的 Token 数量可能会超过 LLM 的上下文限制。为了解决这一问题,我们首先计算输入数据的 Token 数量,如果超出限制,则将数据分批次发送给 LLM。这一策略有效避免了因数据长度超过限制而产生错误。
# 5. 优化 LLM 请求
在最终的请求中,我们将 LLM 的角色设定为资深 DevOps 专家,以提高其处理数据的专业性。同时,我们将请求的 Temperature 参数设置为较低的值(0.2 或 0.3),以确保返回的结果更加确定和精准。

# 6. 结果输出
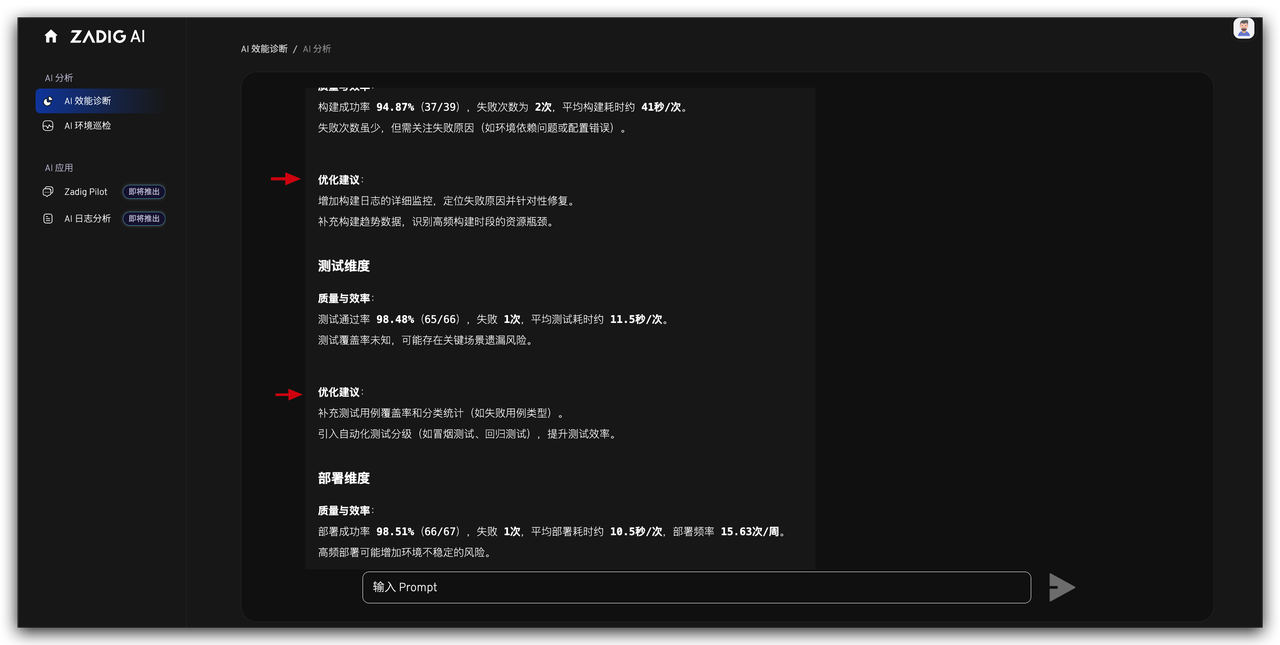
最终,我们将分析结果以 Markdown 格式返回给前端,前端将其渲染为带有格式的文本段落,为用户提供了更加直观和易于理解的分析报告。
# 当前状态及未来
Zadig 的 AI 效能诊断模块已实现智能化分析工程数据,能迅速定位组织效能瓶颈并提供改进建议,同时具备智能数据分析、问题精准定位和科学改进建议等核心能力,可帮助团队提升效能。但在数据处理上存在一些局限性,计算 Token 长度方式可能不适用于 DeepSeek,且数据量过大时分多次请求 LLM 再聚合的方式会造成数据精度损失。
未来 Zadig 计划接入 LLM 的 Stream API,以提高响应速度和用户体验。同时,将继续优化 Prompt,并探索更多创新应用场景,助力企业实现数字化转型,提升核心竞争力。






